CVPRW 2026 · Single-Image Animatable Animal Reconstruction
AniGauss: Toward Animatable Animal Reconstruction from Single In-the-Wild Images via Topology-Aware Gaussians
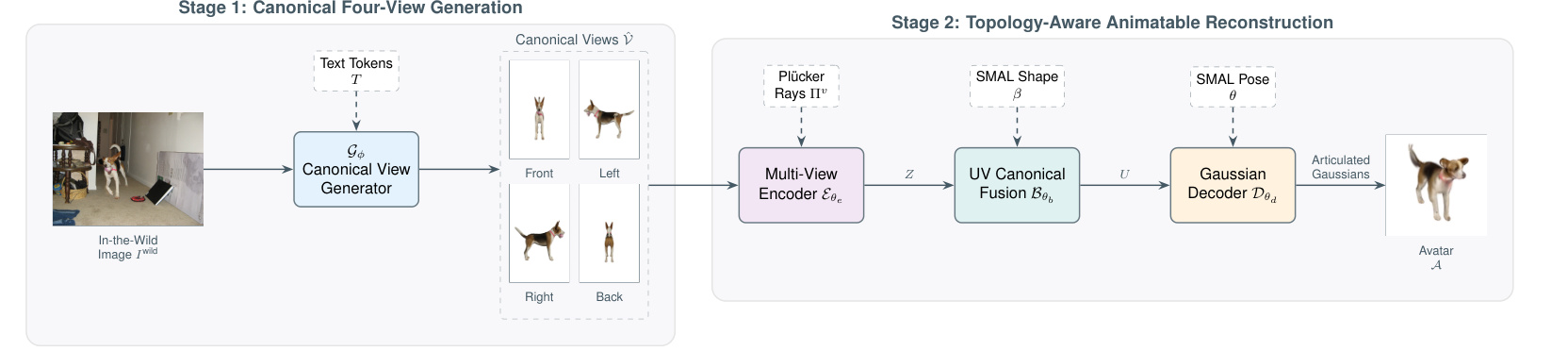
A feed-forward framework that turns one casually captured animal image into a controllable, SMAL-aligned Gaussian avatar by first hallucinating canonical semantic views and then reconstructing topology-aware articulated Gaussians.
1UNIST · 2University of Texas at Austin · 3DGIST
Single in-the-wild image
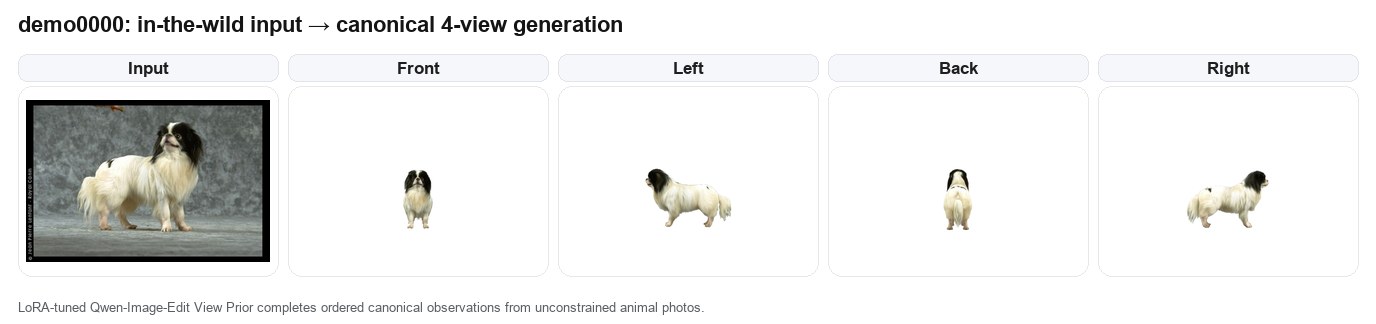
Canonical four-view generation
SMAL topology prior
Animatable Gaussians